- Published on
Edge Computing: Bringing Machine Learning to IoT
- Authors

- Name
- AI Guide
The traditional infrastructure of artificial intelligence has long relied on the centralized cloud. Enormous data centers packed with high-performance GPUs handle incoming data, process complex deep learning algorithms, and pipe predictions back to client devices.
While this centralized approach works perfectly well for generating static text, handling asynchronous API requests, or rendering images on demand, it introduces crippling data transfer bottlenecks for real-time internet of Things (IoT) systems.
As billions of new sensory devices come online, transmitting every raw byte of data across the open internet to a distant cloud cluster is becoming unsustainable. The solution to this systemic scaling crisis is Edge AI—shifting the computational heavy lifting directly to the physical environments where the data is born.
The Three-Tier Architecture Grid
To understand how tasks are distributed between physical environments and centralized corporate mainframes, modern system engineers look at a structured three-tier operational hierarchy.
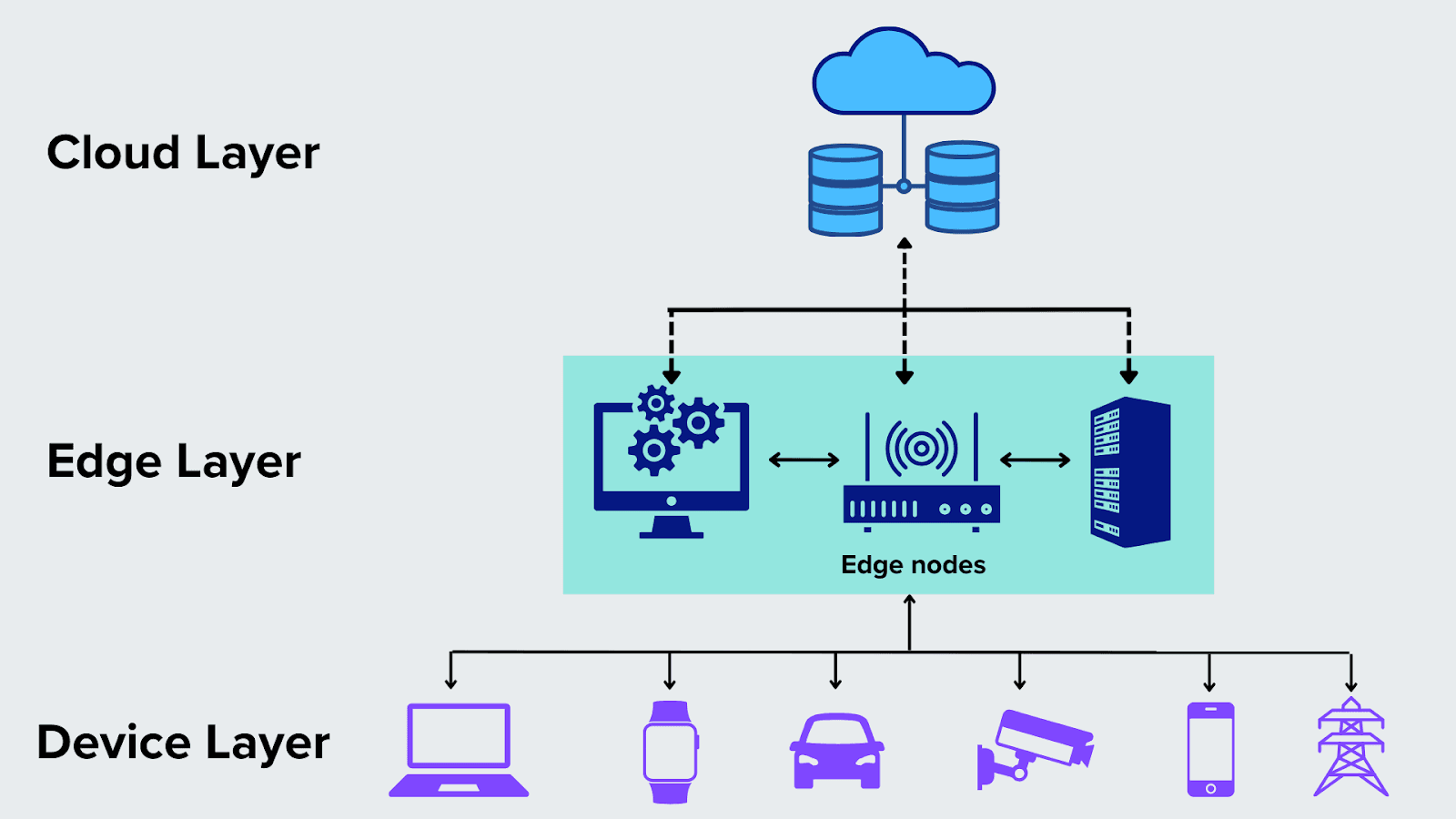
This architectural grid divides computational responsibilities into distinct layers:
- The Device Layer: Comprises local sensory hardware, microcontrollers, embedded cameras, and actuators. These devices capture physical telemetry (temperature, video frames, acoustic signals) but possess highly constrained power budgets and processing capabilities.
- The Edge Layer: Consists of localized entry gateways, mesh routers, and dedicated on-site computing nodes. This layer acts as a low-latency computational buffer, aggregating local sensor information and executing real-time machine learning inference right on the premises.
- The Cloud Layer: Consists of massive decentralized database clusters and deep learning training servers. This layer handles heavy long-term data storage, runs computationally intensive global analytics, and retrains massive base models using aggregated historical datasets.
Crucial Advantages of Processing Data Locally
Transitioning from a pure cloud configuration to a hybrid edge network provides critical computational advantages that are transforming modern digital ecosystems.
1. Eliminating Network Bandwidth Saturation
High-definition security systems, automated manufacturing plants, and autonomous vehicles generate massive quantities of raw sensory metrics every second. Uploading continuous multi-channel raw streams saturates local network bandwidth and leads to staggering cloud storage bill runaways. By running classification layers right on local nodes, edge architectures filter out irrelevant metrics on site, transmitting only highly summarized data packages back to central databases.
2. Achieving Near-Zero Latency
For time-critical autonomous platforms, a delay of even 100 milliseconds spent routing data frames through a cloud server can lead to total system failure. Edge computing brings latency profiles down into the single-digit millisecond range, enabling instant, split-second safety responses that operate completely independently of internet traffic or connection drops.
3. Fortifying Data Privacy and Security
In sensitive operational spaces like medical facilities or private residential areas, transmitting continuous video feeds or diagnostic streams raises immense regulatory compliance issues. Processing raw assets directly on localized node arrays ensures sensitive identifiers never cross the outer firewall, strictly reducing the active digital attack surface.
Engineering Deep Learning Models for Constrained Hardware
Deploying heavy convolutional neural networks or transformer layers onto restricted microcontrollers requires highly specialized model compression and quantization methodologies.
Standard cloud execution models rely on complex floating-point precision arrays ( floats). Edge engineers use advanced structural pruning and integer quantization ( ints) to compress these massive weights down into minor, low-power binary execution files. This structural optimization drops model storage footprints by up to 75% and drastically slashes local cache usage while safely retaining predictive classification accuracy.
An Example of Edge Inference Layout
Using optimized frameworks like TensorFlow Lite or ONNX Runtime, developers initialize pre-compiled model structures directly into device memory for ultra-fast, local loop evaluation:
import tflite_runtime.interpreter as tflite
import numpy as np
# Load the highly compressed, quantized edge model into local memory
interpreter = tflite.Interpreter(model_path="edge_model_quantized.tflite")
interpreter.allocate_tensors()
# Isolate target input/output memory addresses
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Structure the incoming raw sensor matrix
raw_sensor_data = np.array([[0.12, 0.85, 0.44]], dtype=np.float32)
# Execute rapid local prediction loop without cellular/wifi routing
interpreter.set_tensor(input_details[0]['index'], raw_sensor_data)
interpreter.invoke()
# Capture immediate actionable telemetry
prediction_output = interpreter.get_tensor(output_details[0]['index'])
print("Localized Telemetry Output Status:", prediction_output)